浏览器相关问题
1. http 返回码有哪些?
概述
2XX,表示 Success 成功 的状态码。
3XX,表示 Redirection 重定向 的状态码。
4XX,表示 Client Error 客户端错误 的状态码。
5XX,表示 Server Error 服务器错误 的状态码。
200系列有三个,服务器:发全部资源(200),不发资源(204),发范围资源(206)
300系列有五个,服务器的资源:永久重定向(301),临时重定向(302、307),post切换为get后重定向(303),访问不符合条件(304)
400系列有五个,服务器:无法理解(400),权限验证(401),不允许访问(403),没有该资源(404),禁止该方式访问(405)
500系列有三个,服务器:内部故障(500),上游故障(502),正忙(503)
详述
200 OK:服务器端请求已 正常处理。
204 No Content:一般在 只从客户端发送信息, 服务器不需要发送新信息内容 的情况下使用。
206 Partial Content:客户端进行 范围请求,服务端返回 小范围内的资源。
301 Moved Permanently:资源 永久重定向,客户端访问新的地址。
302 Found:资源 临时重定向,客户端暂时访问新地址。
303 See Other:服务器让客户端把 post 请求切换为 get 请求重定向访问新的地址。
304 Not Modified:和重定向关系不大,资源已找到,但未符合条件
307 Temporary Redirect:资源 临时重定向,客户端暂时访问新地址。和 302 类似,有 get 和 post 的访问差别。
400 Bad Request:服务端 无法理解请求报文,可能是格式错误。
401 Unauthorized:客户端需要对访问进行 权限认证。
403 Forbidden:资源不允许访问
404 Not Found:没有找到资源。
405 Method Not Allowed:服务器 禁止使用该访问方式。
500 Internal Server Error:服务完成执行请求时 内部发生了故障。
502 Bad Gateway:“中间商” 服务器(代理服务器、网关服务器),无法访问上游服务器。
503 Service Unavailable:服务器无法处理请求,正忙(超负荷、停机维护)。
2 如何判断一个变量是否为数组?
这道题实际上是在考两个方向的知识点:原型链和类型转换。
以下是 ES5 常用的判断方式。基于原型链,会导致如果绑定原型链后,会判断错误:
var a = [];
var b = {};
b.__proto__ = Array.prototype;
// 方式一
a.constructor === Array; // true,通过原型链访问构造函数来判断
// 方式二
a instanceof Array; // true, instanceof 基于原型链判断,可判断引用类型,
Array.prototype.isPrototypeOf(a); // true,isPrototypeOf 基于原型链判断,a 的原型链上是否有 Array.prototype
// 方式三
Object.getPrototypeOf(a) === Array.prototype; // true,获取原型链,判断是否是 Array.prototype
a.__proto__ === Array.prototype // true,获取原型链,判断是否是 Array.prototype
以下是可以准确判断的方式:
Object.prototype.toString.call(a) === '[object Array]'; // true,通过 toString 方式判断类型,是最常用的方法。
Array.isArray(a) // true,直接判断出
// polyfill
if (!Array.isArray){
Array.isArray = function(arg){
return Object.prototype.toString.call(arg) === '[object Array]';
};
}
3 同源策略和跨域资源共享
1 同源
同源是一种安全机制,为了预防某些恶意行为(例如 Cookie 窃取等),保护用户的隐私。不同源之间的页面,不准互相访问数据。
满足同源要具备三方面:协议相同、域名相同、端口相同。
通过
window.origin或location.origin得到当前源。
http://moxy.com/index.html
http://moxy.com/server.php
//同源
http://a.wang.com
http://wang.com
//不同源,域名必须一模一样
2 跨域
当用户在 A 域中访问服务器获取资源,服务器会正常的返回资源。而当用户试图在其他域的网站去访问 A 域的资源,出于安全原因,服务器就会拒绝这种访问方式。
- 浏览器发送请求时,会把本地域放在请求头中发送给服务器,以便服务器对齐对其进行验证。
可以跨域使用CSS、JS和图片
- 同源策略限制的是数据访问,我们引用
CSS、JS和图片等资源不限制。
同源策略会让三种行为受限:
- Cookie、LocalStorage 和 IndexDB 访问受限
- 无法操作跨域 DOM(常见于 iframe)
- Javascript 发起的 XHR 和 Fetch 请求受限
3 CORS 跨域
"跨域资源共享"(Cross-origin resource sharing)。
- 允许浏览器向跨源服务器,发出
XMLHttpRequest请求,从而克服了AJAX只能同源使用的限制。
服务器的响应请求中设置:"Access-Control-Allow-Origin" = *
实现 CORS 通信需要浏览器和服务器都支持。
3.1 浏览器 CORS
浏览器会限制 从脚本内发起 的跨域 HTTP 请求。 例如 XHR 和 Fetch 就遵循同源策略。这意味着使用 API 的 Web 应用程序只能从加载应用程序的同一个域请求 HTTP 资源。
Web 程序发出跨域请求后,浏览器会 自动 向我们的 HTTP header 添加一个额外的请求头字段:Origin。Origin 标记了请求的站点来源:
GET https://api.website.com/users HTTP/1/1
Origin: https://www.mywebsite.com // <- 浏览器自己加的
服务器返回的 response 也会添加一些响应头字段,这些字段将 显式表明 此服务器是否允许这个跨域请求。
3.2 客户端 CORS
服务器开发人员,通过验证 Origin 是否允许跨域访问,然后在 HTTP 响应中添加额外的响应头字段 Access-Control-* 来表明是否允许跨域请求。
服务器端的设置:
- 如果允许某域名跨域,给该域名加上访问权限:将该域添加到
Access-Control-Allow-Origin中。
3.3 CORS存在的问题
不支持IE8/9,如果要在IE8/9使用CORS跨域需要使用XDomainRequest对象来支持CORS。
4 JSOP 跨域
全称:JSON with padding
利用动态创建 <script> 标签向服务器发送 GET 请求,服务器收到请求后将数据放在一个指定的 回调函数 中并传送回来。
算法相关
1 快排
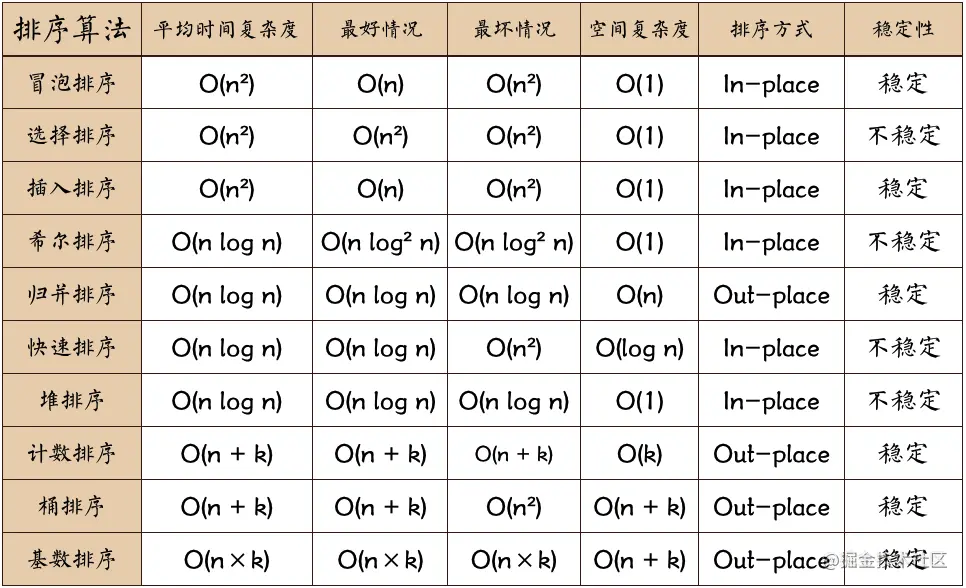
// 原生API: sort() 将元素转换为字符串,然后按照 UTF-16 进行排序。
// 即使数组内容全部是 number,也会转化为 string 然后再进行比较。
["c","b","a","A","C","B",3,2,1].sort()
// (9) [1, 2, 3, 'A', 'B', 'C', 'a', 'b', 'c']
var sortArray = function (nums) {
// 快速排序
let left = 0, right = nums.length - 1;
quickSort(nums, left, right);
return nums;
// 将 [left, right] 排序(切分)
function quickSort(nums, left, right) {
// base case
if (left >= right) return;
const pivotIndex = partition(nums, left, right);
quickSort(nums, left, pivotIndex - 1);
quickSort(nums, pivotIndex + 1, right);
}
// 将 [left, right] 左右归类,返回下标
function partition(arr, left, right) {
// 随机选取基数pivot,并交换位置到第一个:index 为 pivot 的下标
let index = Math.floor((left + right) / 2);
[arr[index], arr[left]] = [arr[left], arr[index]];
const povit = arr[left];
index = left;
left++;
// 循环
while (left <= right) {
while (arr[left] < povit) left++;
while (arr[right] > povit) right--;
if (left <= right) {
[arr[left], arr[right]] = [arr[right], arr[left]];
left++;
right--;
}
}
// 修改基数的位置
[arr[index], arr[right]] = [arr[right], arr[index]];
return right;
}
};
let arr = [5, 43, 7, 60, 5, 3, 21, 8, 1];
console.log(quickSort(arr));
简便方法:
- 快排的特点是原地,这里简便后不是原地快排了。
// 快速排序 2
function quickSort(array) {
if (array.length < 2) {
return array
}
let pivot = array[array.length - 1]
let left = array.filter((value, index) => {
return value <= pivot && index != array.length - 1
})
let right = array.filter((value) => {
return value > pivot
})
return [...quickSort(left), pivot, ...quickSort(right)]
}
2 数组去重
一共有六种方法,逐次优化:
- 双层
for循环; filter+indexOf;sort+ 冒泡;object的key唯一性 +hasOwnProperty+filter;set去重,一行代码解决;reduce- 对象数组去重。
结论1,5 -> 1,速度越来越慢。所以原生的 set 是最快的。
结论2,object 的时间复杂度最低,空间复杂度最高,因为在堆内存中创建了一个 object。
时间复杂度:
O(n^2):双层for、filter+indexOfO(nlogn):sort+ 冒泡(sort在大于10个元素时,使用了快排;小于10个用双重for循环);O(n):object唯一性、reduce对象数组去重、set(new Set()和[...set]都是O(n));
1. 双层 for 循环
效率最低,原理最简单。
const distinct = (arr) => {
len = arr.length;
for (let i = 0; i < len; i++) {
for (let j = i + 1; j < len; j++) {
if (arr[i] == arr[j]) {
arr.splice(j, 1)
// splice 会改变数组长度,所以要将数组长度 len 和下标 j 减一
j--;
len--;
}
}
}
return arr
}
let arr = [1, 5, 2, 7, 3, 87, 2, 3, 5, 7, 9, 3, 2, 5, 7, 8, 4, 2, 4, 6]
console.log(distinct(arr))
//[1, 5, 2, 7, 3, 87, 9, 8, 4, 6]
2. filter + indexOf
filter负责过滤数组indexOf负责判断该元素是否已重复。indexOf会返回 value 对应的 第一个 key,如果 key 不等于当前遍历的 index,则证明该元素之前已经出现过。
function distinct(arr) {
return arr.filter((item, index) => {
return arr.indexOf(item) === index;
});
}
3. sort + 冒泡
sort负责排序,- 冒泡:利用
for对比前后两个元素是否相同 concat:浅拷贝一份数组,sort会修改原数组。
function distinct(arr) {
let res = [];
let sortedArray = arr.concat().sort();
let seen;
for (let i = 0; i < sortedArray.length; i++) {
// 第一个元素 和 前后不相等的元素 放入 res 数组中
if (!i || seen !== sortedArray[i]) {
res.push(sortedArray[i]);
seen = sortedArray[i];
}
}
return res;
}
4. object + hasOwnProperty + filter
- 利用
object的key唯一性,每遍历一个数组成员,就把这个成员的值作为obj的键,对应的值为true; hasOwnProperty判断当前数组成员是否已在object中;filter过滤重复的数组成员。typeof item + item是因为object的key只能是字符串形式,无法区分'123'和123。
function distinct(arr) {
let obj = {};
return arr.filter((item) => {
return obj.hasOwnProperty(typeof item + item)
? false
: (obj[typeof item + item] = true);
});
}
5. set 去重
利用 set 的 key 唯一性对数组去重,效率最高。
// 可以简化为一行代码
function distinct(arr) {
return Array.from(new Set(arr));
}
const unique = (arr) => [...new Set(arr)];
6. reduce - 对象数组去重
- 该方法用于数组的成员是对象,要判断这些对象中的 “主键” 来去重(例子中就是
name的值)。
function distinct(arr) {
let temp = {};
return arr.reduce((prev, curv) => {
if (!temp[curv.name]) {
prev.push(curv);
temp[curv.name] = true;
}
return prev;
}, []);
}
var resources = [
{ name: "张三", age: "18" },
{ name: "张三", age: "19" },
{ name: "张三", age: "20" },
{ name: "李四", age: "19" },
{ name: "王五", age: "20" },
{ name: "赵六", age: "21" },
];
console.log(distinct(resources));
速度分析:
Set < Object 键唯一 < sort + 冒泡 < filter + indexOf < 双重 for 循环
// 分析方法
// arr 利用 from,对刚创建好的数组进行成员初始化: [0, 1, 2, 3, 4, ...]
let arr1 = Array.from(new Array(100000), (x, index)=>{
return index
})
let arr2 = Array.from(new Array(50000), (x, index)=>{
return index+index
})
let start = new Date().getTime()
console.log('开始数组去重')
// 浅拷贝一份原数组
let arr = a.concat(b);
function distinct(arr) {
// 数组去重
}
console.log('去重后的长度', distinct(arr).length)
let end = new Date().getTime()
console.log('耗时', end - start)
去重分析:
NaN 历史遗留问题,自身不相等,NaN 是一个对象。
console.log(NaN == NaN); // false
console.log(NaN === NaN); // false
console.log({} == {}); // false
console.log({} === {}); // false
console.log(/a/ == /a/); // false
console.log(/a/ === /a/); // false
将这样一个数组按照上面的方法去重后的比较:
var array = [1, 1, '1', '1', null, null, undefined, undefined, new String('1'), new String('1'), NaN, NaN];
| 方法 | 结果 | 不去重的部分 |
|---|---|---|
| 双层 for 循环 | [1, "1", null, undefined, String, String, NaN, NaN] | Object 、NaN |
| Array.sort()加一行遍历冒泡 | ["1", 1, String, 1, String, NaN, NaN, null, undefined] | Object、NaN、123 & '123' |
| Array.filter()加 indexOf | [1, "1", null, undefined, String, String] | object,忽略 NaN |
| Object 键值对去重 | [1, "1", null, undefined, String, NaN] | 全部去重 |
| ES6中的Set去重 | [1, "1", null, undefined, String, String, NaN] | object |
Object 对象去重复:时间复杂度
O(n)最低;空间复杂度最高,因为在堆内存中创建了一个对象;Array.filter()+indexOf:时间复杂度O(n^2)。- 因为
indexOf内部是通过 for 循环遍历实现的
- 因为
3. 树的遍历
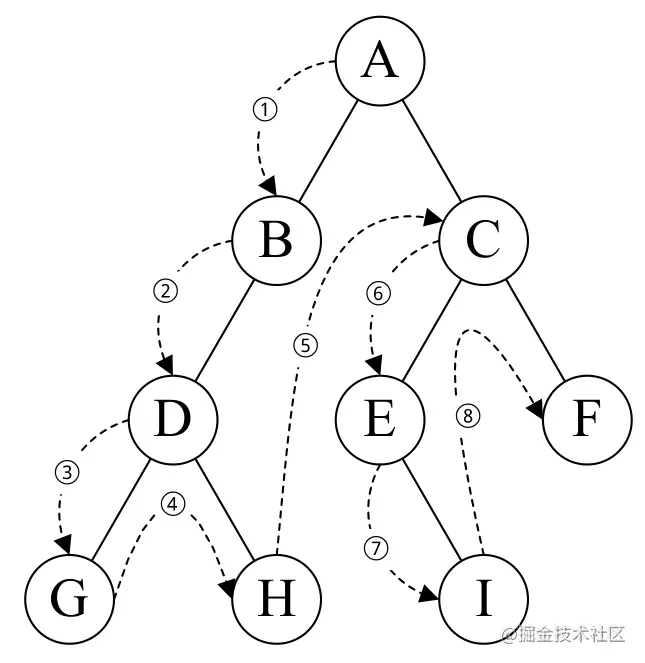
3.1 二叉树的遍历
- 先序遍历:若二叉树为空,则空操作返回,否则先访问根结点,然后前序遍历左子树,再前序遍历右子树。
- https://juejin.cn/post/6844904047107899400
- https://juejin.cn/post/6994744122837827592
const preorderTraversal = function(root) {
const res = []
traversal(root)
return res
function traversal (root) {
if (root !== null) {
res.push(root.val) // 访问根节点的值
traversal(root.left) // 递归遍历左子树
traversal(root.right) // 递归遍历右子树
}
}
}
3.2 遍历 JSON 中查找 value
// 查找 200
function findItems(list, targetValue){
let res = [];
traversal(res, list, targetValue);
return res
function traversal(res, list, targetValue) {
for (let item of list) {
const { value, children, label } = item;
if (value && value === targetValue)
res.push({ label, value });
if (Array.isArray(children) && children.length)
traversal(res, children, targetValue);
}
}
}
const res = findItems(list, 200)
console.log(res) // [{label: '财务部', value: 200}]
数据:
const list = [{
"value": 192,
"label": "技术部",
"children": [{
"value": 193,
"label": "软件组",
"children": [{
"value": 195,
"label": "软件一组"
},
{
"value": 196,
"label": "软件二组"
}
]
},
{
"value": 198,
"label": "运维组"
}
]
},
{
"value": 200,
"label": "财务部",
"children": [{
"value": 201,
"label": "会计"
},
{
"value": 203,
"label": "出纳"
}
]
},
{
"value": 300,
"label": "人资部",
"children": [{
"value": 301,
"label": "行政"
},
{
"value": 302,
"label": "人资"
}
]
}
]
4. 深拷贝、浅拷贝
https://juejin.cn/post/6844903692756336653#heading-4
浅拷贝
使用 for...in 和 hasOwnProperty 遍历:
for..in常用于遍历对象,会遍历包括原型链上的所有可枚举的属性,不遍历symbol。for...of常用于遍历数组,用in遍历数组会打乱数组顺序。不能遍历对象,对象默认没有iterable
const shallowClone = (obj) => {
const newObj = {}
for (const key in obj) {
if (Object.hasOwnProperty.call(obj, key)) {
newObj[key] = obj[key];
}
}
return newObj
}}
let a1 = {b: {c: {}}};
let a2 = shallowClone(a1)
a1.b === a2.b // true
扩展运算符
{...obj},Object.assign(),常见的数组 API (
array.concat()、array.slice()等)
深拷贝
方法一:JSON.parse()
let obj2 = JSON.parse(JSON.stringify(obj));
问题:
- 循环引用;
- 共同引用(见方法三的阐述);
- 不能序列化:
undefined、symbol、function,直接忽略。 - 不可枚举的属性默认会被忽略
NaN和Infinity格式的数值会被当做null- 如果对象属性有
toJSON方法,那么该方法就会替代默认的序列化行为 - 栈溢出。
// 循环引用问题
let obj1 = {};
let obj2 = { b: obj1 };
obj1.a = obj2;
JSON.stringify(obj1);
/* VM5438:1 Uncaught TypeError: Converting circular structure to JSON
--> starting at object with constructor 'Object'
| property 'a' -> object with constructor 'Object'
--- property 'b' closes the circle
at JSON.stringify (<anonymous>)
at <anonymous>:1:6 **/
解决 JSON 的循环引用问题:
- 缓存中保存所有遇到的
object,每次添加一个object到cache中时,就判断cache中是否已经保存过该对象,如果保存过,则丢弃该对象。
const toJSON = (obj) => {
let cache = [];
const res = JSON.parse(JSON.stringify(obj, (index, item) => {
if (typeof item === "object" && item !== null) {
if (cache.indexOf(item) !== -1) {
// 说明缓存中已经有该值
// 移除,或对这个值进行处理后再 push。
return;
}
// 收集所有的值
cache.push(item);
}
return item;
})
);
cache = null; // 清空变量,便于垃圾回收机制回收
return res;
};
let b1 = {};
let b2 = { a: b1 };
b1.a = b2;
let newObj = toJSON(b2); // 可以正确使用
let newObj = JSON.parse(JSON.stringify(b1)); // 这里会报错
- 注意,
stringify中的回调函数,参数是(key, vale)这个顺序和数组的 API 中回调函数 (item, index)相反。
方法二:浅拷贝 + 递归
- 效果和 JSON 的方法基本相同。
- 有栈溢出的问题。
当遍历到一个成员时,赋值前先进行类型判断,如果是 object,则递归调用函数。
const shallowClone = (obj) => {
const res = []
for (const key in obj) {
if (Object.hasOwnProperty.call(obj, key)) {
if (Object.prototype.toString.call(obj[key]) === "[object Object]") {
res[key] = shallowClone(obj[key])
} else {
res[key] = obj[key]
}
}
}
return res
}
let demo = {
name: 'dayday',
book: {
title: 'Do you really Know JS',
price: "45"
}
}
let res = shallowClone(demo)
res.book === demo.book // false,共同引用问题, JSON 方法也有
方法三:解决栈溢出
破解递归爆栈的方法有两条路:
- 消除尾递归,但在这个例子中貌似行不通,
- 不用递归,改用循环,这里就是把递归改造为了 栈 + 循环遍历栈。
几个记忆要点:
- 栈、根等等值为对象的定义,全部用
const - 遍历对象成员,用
for..in..+Object.prototype.hasOwnProperty.call() - 在(循环+入栈+复制)时,使用了两次
if,第一次判断hasOwnProperty,第二次判断tyeof "object"。
记忆结构:
- 定义(2)
- 根:
root={} - 栈:
loopList=[...]<==={parent、key、data}
- 根:
- 循环栈(3)
- 定义(2):出栈 (node) + 解构(parent、key、data)
- 创建 res ===> 判断
typeof key === "undefined",确定父节点。 - 遍历 data(2)
- 判断
hasOwnProporty遍历对象的一环; - 判断
typeof data[k] === "object"是否为object; ===> 出栈 + 复制
- 判断
- 返回:
root
function cloneLoop(x) {
const root = {};
// 栈
const loopList = [
{
parent: root,
key: undefined,
data: x,
},
];
while (loopList.length) {
// 深度优先,出栈
const node = loopList.pop();
const { parent, key, data } = node;
// key 如果是undefined,表明当前节点直接在root中(根节点的子节点);
// 如果有值,表明这个值就是当前节点在父元素中的key(指针)
// 初始化赋值目标,key 为 undefined 则直接成为父元素,否则添加这个 key 为父元素内的一个 key
let res;
if (typeof key === "undefined") {
res = parent;
} else {
res = parent[key] = {};
}
for (let k in data) {
if (data.hasOwnProperty(k)) {
if (typeof data[k] === "object") {
// 入栈
loopList.push({ parent: res, key: k, data: data[k]});
} else {
res[k] = data[k];
}
}
}
}
return root;
}
let newList = cloneLoop(list);
方法四:终极办法
- 解决共同引用 + 栈溢出
假如一个对象a,a下面的两个键值都引用同一个对象b,经过深拷贝后,a的两个键值会丢失引用关系,从而变成两个不同的对象。
var b = {};
var a = {a1: b, a2: b};
a.a1 === a.a2 // true
var c = clone(a);
c.a1 === c.a2 // false
如果我们发现个新对象就把这个对象和他的拷贝存下来,每次拷贝对象前,都先看一下这个对象是不是已经拷贝过了,如果拷贝过了,就不需要拷贝了,直接用原来的,这样我们就能够保留引用关系。
- 引入一个数组
uniqueList用来存储已经拷贝的对象,每次循环遍历时,先判断对象是否在uniqueList中 ,如果在的话就不执行拷贝逻辑了,而是直接拿uniqueList中的这个对象;uniqueList数组中,每个成员代表一个已经被拷贝过,并放到新对象上的节点。其内部又有两个成员:source:原对象中的这个节点,用来对比原对象中的其他节点,是否相同。target:新对象中的这个节点,如果source对比相同,则不执行新的拷贝,而是把这个target放到新对象上。
find用来遍历uniqueList,通过对比unique.source找是否有相同共同引用。
是方法三的进一步优化,在 ===== 之间的就是额外增加的部分
// 保持引用关系
function cloneForce(x) {
const uniqueList = []; // 用来去重
let root = {};
// 循环数组
const loopList = [{
parent: root,
key: undefined,
data: x,
}];
while (loopList.length) {
// 深度优先
const node = loopList.pop();
const { parent, key, data } = node;
// 初始化res
let res;
if (typeof key == "undefined") {
res = parent;
} else {
res = parent[key] = {};
}
// ============= 判断是否已经存在当前节点的数据
let uniqueData = find(uniqueList, data);
// 数据已存在
if (uniqueData) {
parent[key] = uniqueData.target;
continue; // 复制结束,跳过本次while循环
}
// 数据不存在:保存源数据,在拷贝数据中对应的引用
uniqueList.push({ source: data, target: res });
// =============
for (let k in data) {
if (data.hasOwnProperty(k)) {
if (typeof data[k] === 'object') {
// 下一次循环
loopList.push({ parent: res, key: k, data: data[k] });
} else {
res[k] = data[k];
}
}
}
}
return root;
}
// ======== 查找重复 =========
function find(arr, item) {
for (let unique of arr) {
// 找到重复,则直接复制 unique.target
if (unique.source === item) return unique;
}
return null;
}
// ========
let newList = cloneForce(list)
在代码中,如果数据不存在:
- 保存源数据,在拷贝数据中对应的引用
- source:保存原数据,target:保存复制后的数据。
- 用原对象的数据(source)判断是否存在,用复制后的数据(target)赋值到新对象上。
| JSON.parse | 浅拷贝+递归 | cloneLoop | cloneForce | |
|---|---|---|---|---|
| 难度 | ☆ | ☆☆ | ☆☆☆ | ☆☆☆☆ |
| 兼容性 | ie6 | ie8 | ie6 | ie6 |
| 循环引用 | 不支持 | 一层 | 一层 | 支持 |
| 栈溢出 | 会 | 会 | 不会 | 不会 |
| 保持引用 | 否 | 否 | 否 | 是 |
| 适合场景 | 一般数据拷贝 | 一般数据拷贝 | 层级很多 | 保持引用关系 |
5. 实现 Sleep
sleep 函数可以使程序暂停执行,等到指定的时间后再重新执行,能起到延时的效果。
在很多的编程语言里都提供了 Sleep 函数,如 C/C++ 中的 Sleep() 函数,linux 中的 sleep() 函数。
实际上就是异步编程的优缺点
回调函数方式
在 JavaScript 语言中,原生提供了 setTimeout() 方法来实现一段时间后执行某个任务,但这种写法需要提供回调函数,写法上很不优雅。
setTimeout(console.log("go on.."), 1000)
- 回调地狱,不符合人的思维习惯;
Async + Promise 方式
- 实现间隔 1s 输出:
1,2,3 await实际上是promise的语法糖,把promise的.then()链条变成了符合直觉的同步形式。await必须在async环境下使用,所以通过void创建一个IIFE
// 一行代码:
const sleep = (delay) => new Promise((resolve) => setTimeout(resolve, delay))
// 意思是一样的:
const sleep = (delay) => {
return new Promise((resolve, reject) => {
setTimeout(() => resolve(), delay);
});
};
void async () => {
console.log(1);
await sleep(1000);
console.log(2);
await sleep(1000);
console.log(3);
}();